http-连接管理
概述
http连接的几种方式:串行连接、并行连接、持久连接、管道化连接……
分类
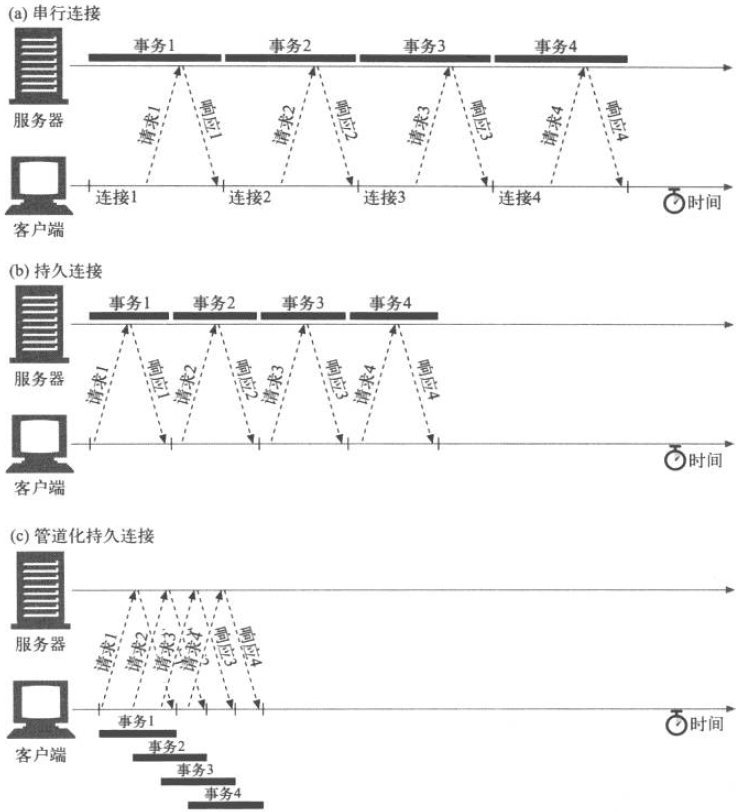
串行连接
也称为短连接、短轮询。
HTTP事务需要按顺序进行传输,等待服务端完成处理并回传。
缺点:
每次HTTP通信后都要断开TCP连接,所以每个新的HTTP请求都需要建立一个新的tcp连接,极大的增加了通信开销。
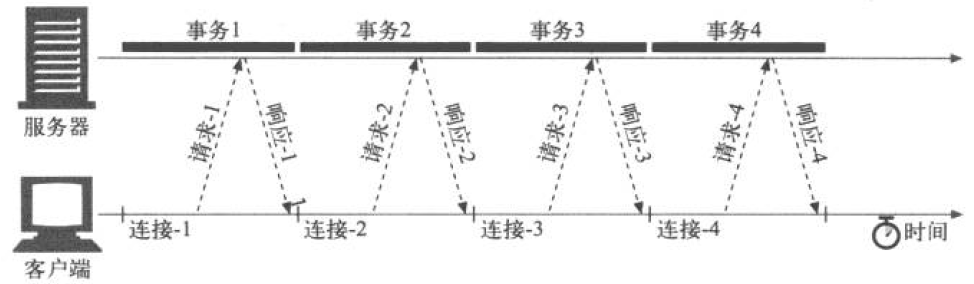
并行连接
并发的执行多条HTTP请求,且每个请求都有自己的TCP连接。
特点:
并行连接的速度可能会更快,但不一定总是更快。
实际上多条连接会产生一些额外的开销,使用并行连接装载整个页面所需的时间很可能比串行下载的时间更长。
如果并行加载多个对象,每个对象都会去竞争这有限的带宽,每个对象都会以比较慢的速度按比例加载,这样带来的性能提升就很小,甚至没什么提升。
而且打开大量连接会消耗很多内存资源,从而引发自身的性能问题。
假如一百个用户同时发出申请,每个用户打开100个连接,服务器就要处理10 000个连接。这会造成服务器性能的严重下降。
实际上,浏览器确实使用了并行连接,但它们并行连接的总数限制为一个较小的值(通常是4个)。
服务器可以随意的关闭来自特定客户端的超量连接。
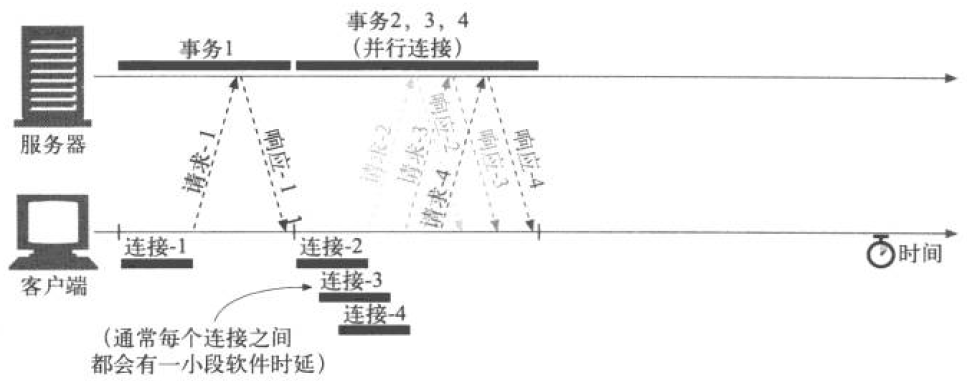
持久连接
也叫长连接、长轮询
在事务处理结束之后仍然保持在打开状态的TCP连接称为持久连接。
方式
持久连接有两种方式,分别为HTTP/1.0+的“Keep-alive”连接,以及HTTP/1.1的“persistent”连接。
Keep-alive:该首部只是请求将连接保持在活跃状态,客户端和服务端可以随时关闭空闲的Keep-alive连接。
限制和规则:
1、必须客户端发送一个Connection:Keep-alive请求首部来激活Keep-alive连接,服务端不一定答应启用Keep-Alive会话;
2、必须随每个希望保持持久连接的请求的头部一起发送,如果某个请求没有带Keep-Alive头部,则服务器会在这个请求后关闭该连接。
Persistent:该首部默认情况下是激活的,除非特别指明,否则HTTP/1.1假定所有连接都是持久的。
限制和规则:
1、发送了 Connection: close 请求首部之后,客户端就无法在那条连接上发送更多的请求了。
如果客户端不想在连接上发送其他请求了,就应该在最后一条请求中发送一个Connection: close 请求首部。
2、只有当连接上所有的报文都有正确的、自定义报文长度时——也就是说,实体主体部分的长度都和相应的Content-Length 一致,或者是用分块传输编码方式编码的——连接才能持久保持。

管道化连接
在持久连接的基础上可选的使用请求管道。在响应到达之前,可以将多条请求放入队列。
限制:
1、如果HTTP客户端无法确认连接是持久的,就不应该使用管道。
2、必须按照与请求相同的顺序回送HTTP响应。HTTP报文中没有序列号标签,因此如果收到的响应失序了,就没办法将其与请求匹配起来了。
3、HTTP 客户端必须做好连接会在任意时刻关闭的准备,还要准备好重发所有未完成的管道化请求。如果客户端打开了一条持久连接,并立即发出了10条请求,服务器可能在只处理了,比方说,5条请求之后关闭连接。剩下的5 条请求会失败,客户端必须能够应对这些过早关闭连接的情况,重新发出这些请求。
4、HTTP 客户端不应该用管道化的方式发送会产生副作用的请求(比如POST)。总之,出错的时候,管道化方式会阻碍客户端了解服务器执行的是一系列管道化请求中的哪一些。由于无法安全地重试POST这样的非幂等请求,所以出错时,就存在某些方法永远不会被执行的风险。
幂等请求
所谓幂等就是 多次执行对资源的影响,和一次执行对资源的影响相同。不管进行多少次重复操作,都是实现相同的结果。
幂等保证在pipeline中的所有请求可以不必关心发送次序和到达服务器后执行的次序,即使多次请求,返回的结果一直是一样的。
反之,若其中包含了不幂等的请求,两个请求,第一个是更新用户张三信息,第二请求是获取更新后的张三最新信息。 他们是按照次序顺序在服务器端执行的:1先执行,2紧接着执行。 但是后一个请求不会等前一个请求完成才执行, 即可能 获取张三最新信息的2号请求先执行完成,这样返回的信息就不是期望的了。
所有请求虽然是按次序到达执行,但是不能保证一定是按照次序依次执行,比如1,2两个请求顺序到达,1是更新用户信息,2是获取这个更新用户的最新信息,1先执行,2不等1执行完就开始执行,得到的用户信息是旧的。
即,依次发了1,2,3这三个请求。如果1和2和3不是幂等的,即2可能要依赖1的返回,3可能要依赖1和2的返回,此种情况下就不能通过pipeline来进行发送。
REST请求按幂等区分
GET请求很好理解,对资源做查询多次,此实现的结果都是一样的。
PUT请求的幂等性可以这样理解,将A修改为B,它第一次请求值变为了B,再进行多次此操作,最终的结果还是B,与一次执行的结果是一样的,所以PUT是幂等操作。
DELETE请求,第一次将资源删除后,后面多次进行此删除请求,最终结果是一样的,将资源删除掉了。
POST不是幂等操作,因为一次请求添加一份新资源,二次请求则添加了两份新资源,多次请求会产生不同的结果,因此POST不是幂等操作。
比较容易混淆的是HTTP POST和PUT。POST和PUT的区别容易被简单地误认为“POST表示创建资源,PUT表示更新资源”;而实际上,二者均可用于创建资源,更为本质的差别是在幂等性方面。在HTTP规范中对POST和PUT是这样定义的:
The POST method is used to request that the origin server accept the entity enclosed in the request as a new subordinate of the resource identified by the Request-URI in the Request-Line ...... If a resource has been created on the origin server, the response SHOULD be 201 (Created) and contain an entity which describes the status of the request and refers to the new resource, and a Location header.
The PUT method requests that the enclosed entity be stored under the supplied Request-URI. If the Request-URI refers to an already existing resource, the enclosed entity SHOULD be considered as a modified version of the one residing on the origin server. If the Request-URI does not point to an existing resource, and that URI is capable of being defined as a new resource by the requesting user agent, the origin server can create the resource with that URI.
POST所对应的URI并非创建的资源本身,而是资源的接收者。比如:POST createArticles的语义是在目标网站下创建一篇帖子,HTTP响应中应包含帖子的创建状态以及帖子的URI。两次相同的POST请求会在服务器端创建两份资源,它们具有不同的URI;所以,POST方法不具备幂等性。而PUT所对应的URI是要创建或更新的资源本身。比如:PUT updateArticles/4231的语义是创建或更新ID为4231的帖子。对同一URI进行多次PUT的副作用和一次PUT是相同的;因此,PUT方法具有幂等性。